Introduction to Supercomputing
Overview
Teaching: 60 min
Exercises: 30 minTopics
What is High-Performance Computing?
What is an HPC cluster or Supercomputer?
How does my computer compare with an HPC cluster?
Which are the main concepts in High-Performance Computing?
Objectives
Learn the components of the HPC
Learn the basic terminology in HPC
High-Performance Computing
In everyday life, we are doing calculations. Before paying for some items, we may be interested in the total price. For that, we can do the sum on our heads, on paper, or by using the calculator that is now integrated into today’s smartphones. Those are simple operations. To compute interest on a loan or mortgage, we could better use a spreadsheet or web application to calculate loans and mortgages. There are more demanding calculations like those needed for computing statistics for a project, fitting some experimental values to a theoretical function, or analyzing the features of an image. Modern computers are more than capable of these tasks, and many friendly software applications are capable of solving those problems with an ordinary computer.
Scientific computing consists of using computers to answer questions that require computational resources. Several of the examples given fit the definition of scientific computations. Experimental problems can be modeled in the framework of some theory. We can use known scientific principles to simulate the behavior of atoms, molecules, fluids, bridges, or stars. We can train computers to recognize cancer on images or cardiac diseases from electrocardiograms. Some of those problems could be beyond the capabilities of regular desktop and laptop computers. In those cases, we need special machines capable of processing all the necessary computations in a reasonable time to get the answers we expect.
When the known solution to a computational problem exceeds what you can typically do with a single computer, we are in the realm of Supercomputing, and one area in supercomputing is called High-Performance Computing (HPC).
There are supercomputers of the most diverse kinds. Some of them do not resemble at all what you can think about a computer. Those are machines designed from scratch for very particular tasks, all the electronics are specifically designed to run very efficiently a narrow set of calculations, and those machines could be as big as entire rooms.
However, there is a class of supercomputers made of machines relatively similar to regular computers. Regular desktop computers (towers) aggregated and connected with some network, such as Ethernet, were one of the first supercomputers built from commodity hardware. These clusters were instrumental in developing the cheaper supercomputers devoted to scientific computing and are called Beowulf clusters.
When more customized computers are used, those towers are replaced by slabs and positioned in racks. To increase the number of machines on the rack, several motherboards are sometimes added to a single chassis, and to improve performance, very fast networks are used. Those are what we understand today as HPC clusters.
In the world of HPC, machines are conceived based on the concepts of size and speed. The machines used for HPC are called Supercomputers, big machines designed to perform large-scale calculations. Supercomputers can be built for particular tasks or as aggregated or relatively common computers; in the latter case, we call those machines HPC clusters. An HPC cluster comprises tens, hundreds, or even thousands of relatively normal computers, especially connected to perform intensive computational operations and using software that makes these computers appear as a single entity rather than a network of independent machines.
Those computers are called nodes and can work independently of each other or together on a single job. In most cases, the kind of operations that supercomputers try to solve involves extensive numerical calculations that take too much time to complete and, therefore, are unfeasible to perform on an ordinary desktop computer or even the most powerful workstations.
Anatomy of an HPC Cluster
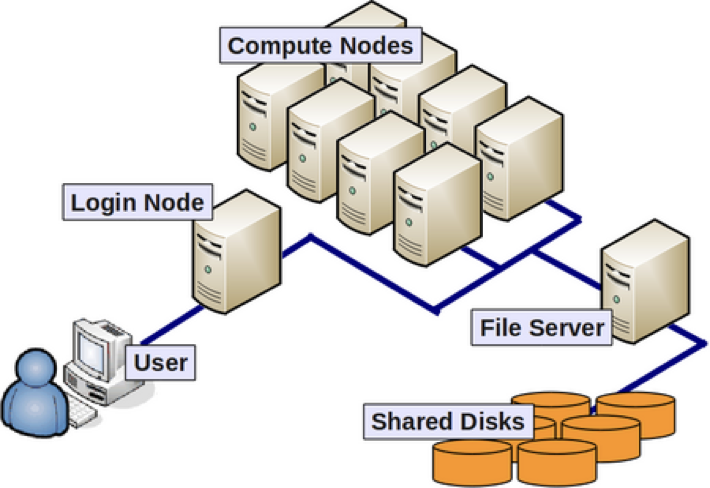
The diagram above shows that an HPC cluster comprises several computers, here depicted as desktop towers. Still, in modern HPC clusters, those towers are replaced by computers that can be stacked into racks. All those computers are called nodes, the machines that execute your jobs are called “compute nodes,” and all other computers in charge of orchestration, monitoring, storage, and allowing access to users are called “infrastructure nodes.” Storage is usually separated into nodes specialized to read and write from large pools of drives, either mechanical drives (HDD), solid-state drives (SSD), or even a combination of both. Access to the HPC cluster is done via a special infrastructure node called the “login node.” A single login node is enough in clusters serving a relatively small number of users. Larger clusters with thousands of users can have several login nodes to balance the load.
Despite an HPC cluster being composed of several computers, the cluster itself should be considered an entity, i.e., a system. In most cases, you are not concerned about where your code is executed or whether one or two machines are online or offline. All that matters is the capacity of the system to process jobs, execute your calculations in one of the many resources available, and deliver the results in a storage that you can easily access.
What are the specifications of my computer?
One way of understanding what Supercomputing is all about is to start by comparing an HPC cluster with your desktop computer. This is a good way of understanding supercomputers’ scale, speed, and power.
The first exercise consists of collecting critical information about the computer you have in front of you. We will use that information to identify the features of our HPC cluster. Gather information about the CPU, number of Cores, Total RAM, and Hard Drive from your computer.
You can see specs for our cluster Thorny Flat
Try to gather an idea of the Hardware present on your machine and see the hardware we have on Thorny Flat.
Here are some tricks to get that data from several Operating Systems
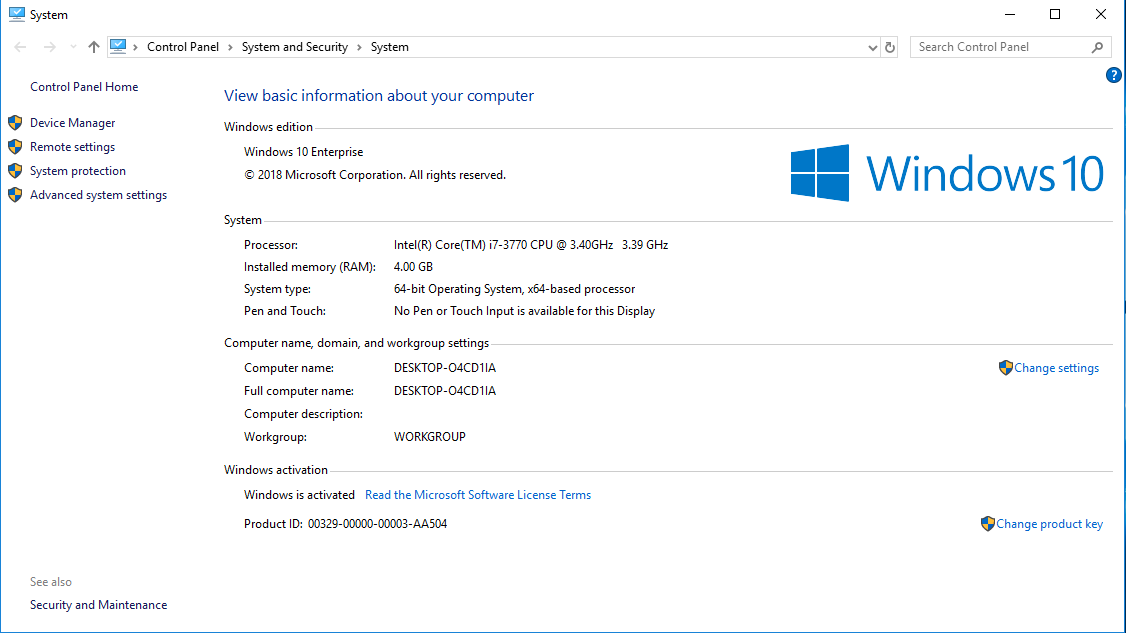
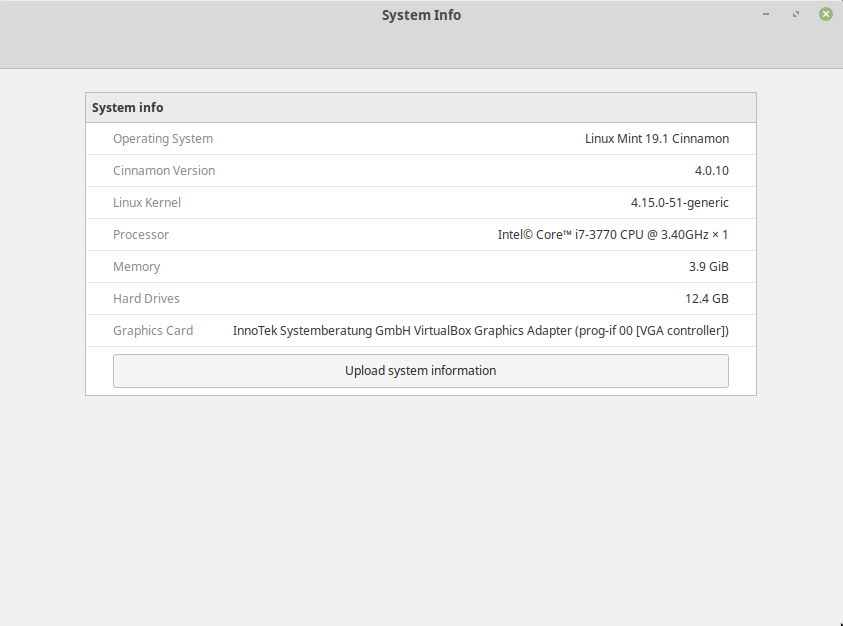
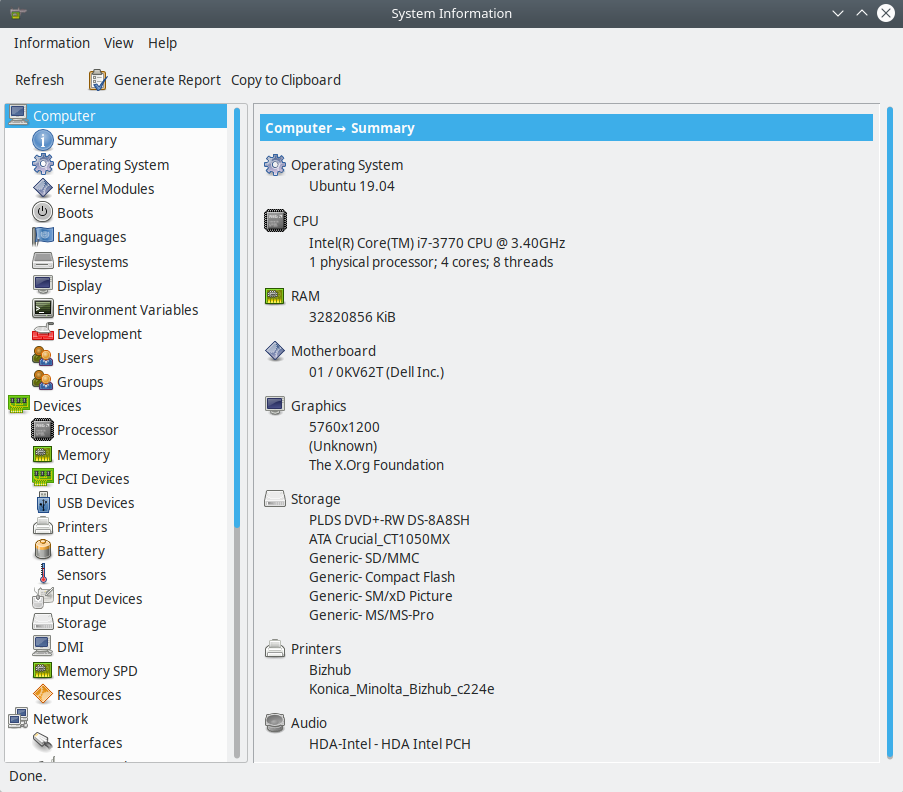
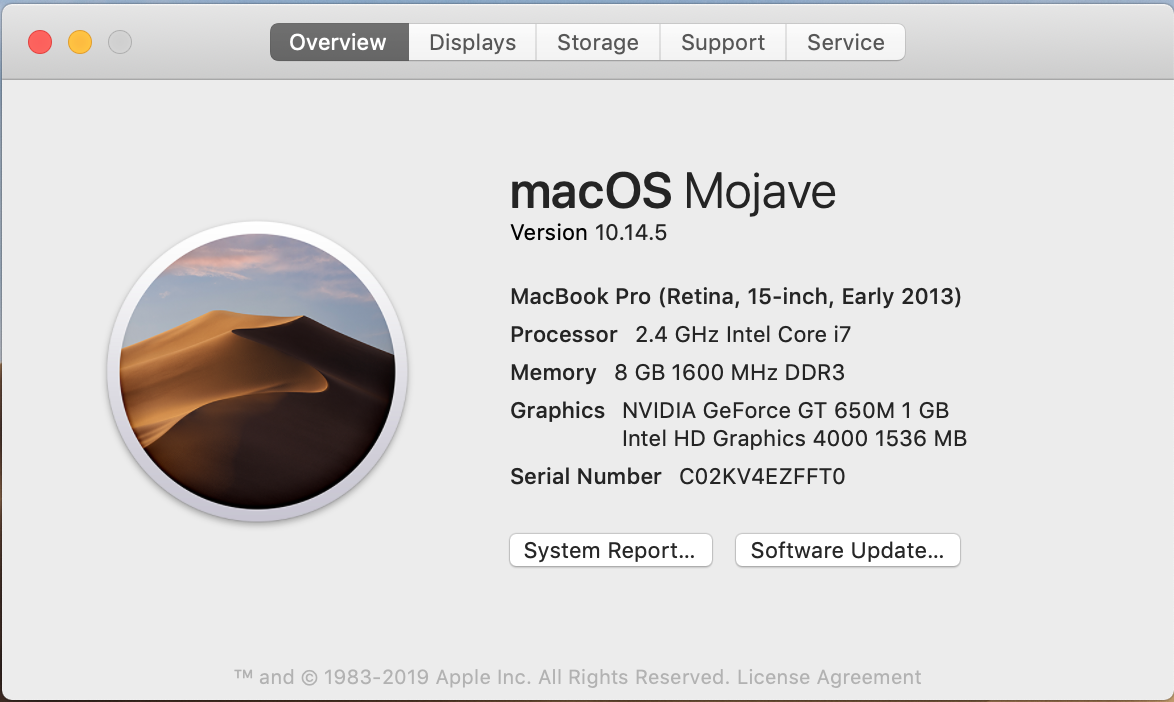 If you want more data click on "System Report..." and you will get:
If you want more data click on "System Report..." and you will get:
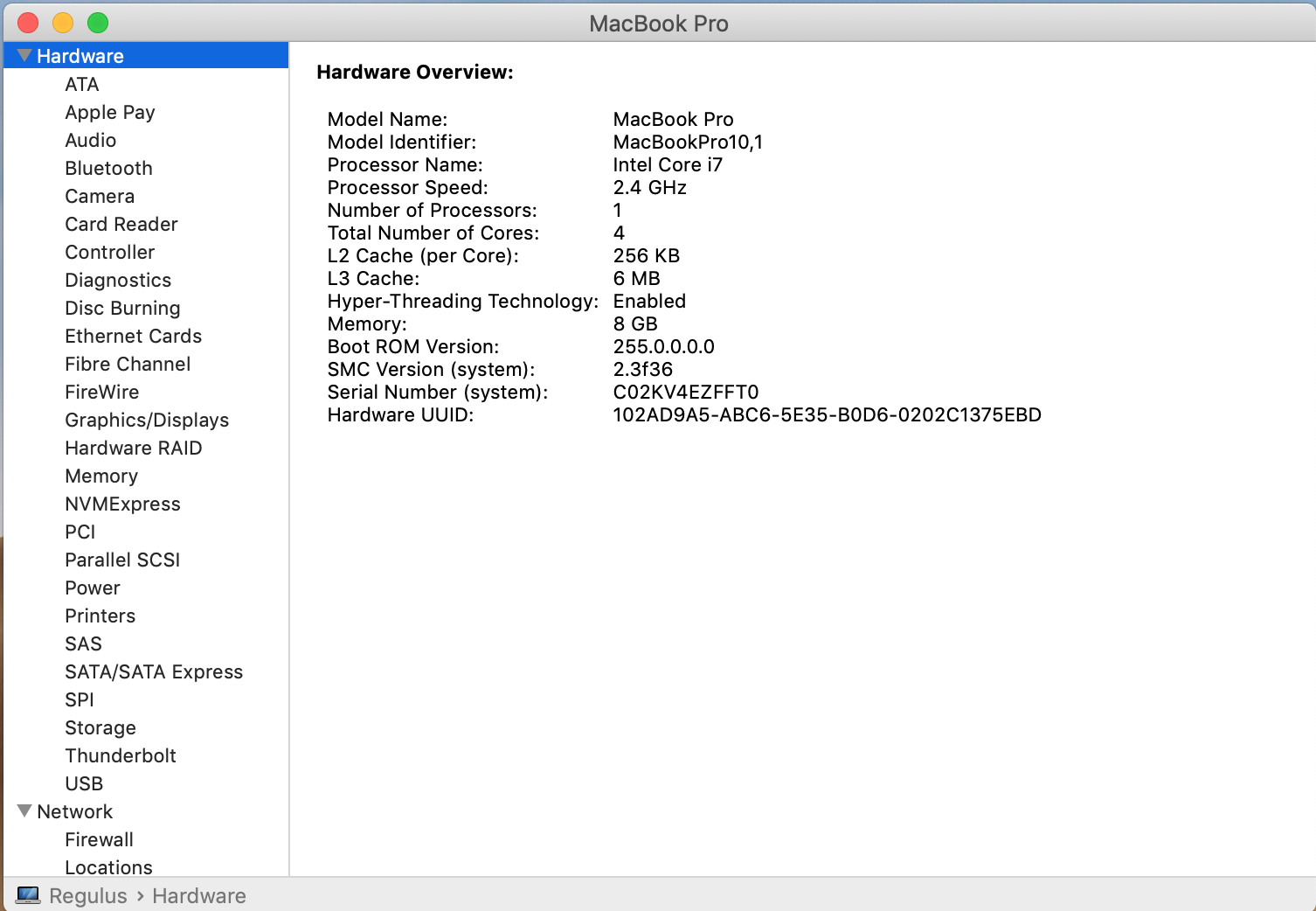
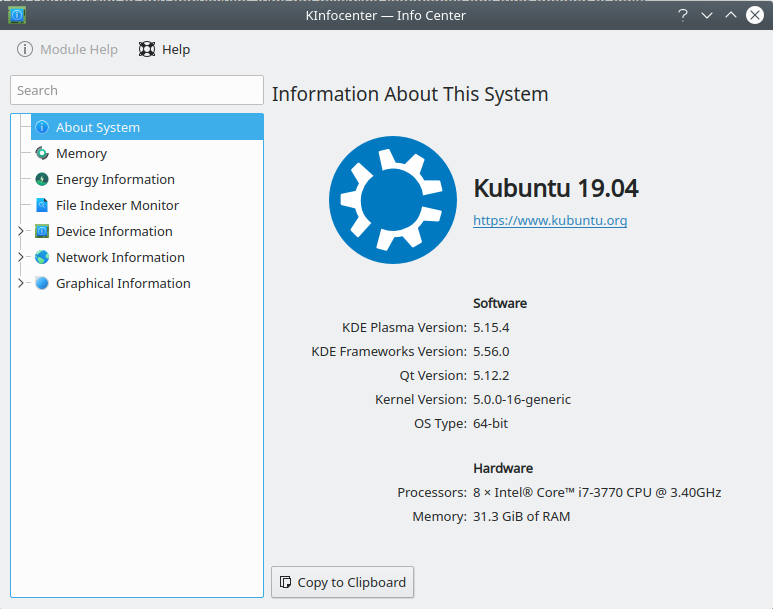
In Linux, gathering the data from a GUI depends much more on the exact distribution you use. Here are some tools that you can try:
KDE Info Center
Linux Mint Cinnamon System Info
Linux Mint Cinnamon System Info
Advantages of using an HPC cluster for research
Using a cluster often has the following advantages for researchers:
- Speed. An HPC cluster has many more CPU cores, often with higher performance specs, than a typical laptop or desktop, HPC systems can offer significant speed up.
- Volume. Many HPC systems have processing memory (RAM) and disk storage to handle large amounts of data. Many GB of RAM and TeraBytes (TB) storage is available for research projects. Desktop computers rarely achieve the same amount of memory and storage.
- Efficiency. Many HPC systems operate a pool of resources drawn on by many users. In most cases when the pool is large and diverse enough, the resources on the system are used almost constantly. A healthy HPC system usually achieves utilization on top of 80%. A normal desktop computer is idle for most of the day.
- Cost. Bulk purchasing and government funding mean that the cost to the a research community for using these systems is significantly less than it would be otherwise. There are also economies done in terms of energy and human maintenance costs compared with desktop computers
- Convenience. Maybe your calculations take a long time to run or are otherwise inconvenient to run on your personal computer. There’s no need to tie up your computer for hours when you can use someone else’s instead. Running on your machine could make it impossible to use it for other common tasks.
Compute nodes
On an HPC cluster, we have many machines, and each of them is a perfectly functional computer. It runs its copy of the Operating System, its mainboard, memory, and CPUs. All the internal components are the same as inside a desktop or laptop computer. The difference is subtle details like heat management systems, remote administration, subsystems to notify errors, special network storage devices, and parallel filesystems. All these subtle, important, and expensive differences make HPC clusters different from Beowulf clusters and normal PCs.
There are several kinds of computers in an HPC cluster. Most machines are used for running scientific calculations and are called Compute Nodes. A few machines are dedicated to administrative tasks, controlling the software that distributes jobs in the cluster, monitoring the health of all compute nodes, and interacting with the distributed storage devices. Among those administrative nodes, one or more are dedicated to be the front door to the cluster; they are called Head nodes. On HPC clusters with small to medium size, just one head node is enough; on larger systems, we can find several Head nodes, and you can end up connecting to one of them randomly to balance the load between them.
It would be best if you never ran intensive operations on the head node. Doing so will prevent the node from fulfilling its primary purpose, which is to serve other users, giving them access and allowing them to submit and manage the jobs running on the cluster. Instead of running on the head node, we use special software to submit jobs to the cluster, a queue system. We will discuss them later on in this lesson.
Central Processing Units
CPU Brands and Product lines
Only two manufacturers hold most of the market for PC consumer computing: Intel and AMD. Several other manufacturers of CPUs offer chips mainly for smartphones, Photo Cameras, Musical Instruments, and other very specialized Supercomputers and related equipment.
More than a decade ago, speed was the main feature used for marketing purposes on a CPU. That has changed as CPUs are not getting much faster due to faster clock speed. It is hard to market the performance of a new processor with a single number. That is why CPUs are now marketed with “Product Lines” and the “Model numbers.” Those numbers bear no direct relation to the actual characteristics of a given processor.
For example, Intel Core i3 processors are marketed for entry-level machines that are more tailored to basic computing tasks like word processing and web browsing. On the other hand, Intel’s Core i7 and i9 processors are for high-end products aimed at top-of-the-line gaming machines, which can run the most recent titles at high FPS and resolutions. Machines for enterprise usage are usually under the Xeon Line.
On AMD’s side, you have the Athlon line aimed at entry-level users, From Ryzen(TM) 3 for essential applications to the Ryzen(TM) 9, designed for enthusiasts and gamers. AMD also has product lines for enterprises like EPYC Server Processors.
Cores
Consumer-level CPUs up to the 2000s only had one core, but Intel and AMD hit a brick wall with incremental clock speed improvements. The heat and power consumption scales non-linearly with the CPU speed. That brings us to the current trend: CPUs now have two, three, four, eight, or sixteen cores on a single CPU instead of a single core. That means each CPU (in marketing terms) is several CPUs (in actual component terms).
There is a good metaphor, but I cannot claim it as mine, about CPUs, Cores, and Threads. The computer is like a Cooking Room; the cooking room could have one stove (CPUs) or several stoves (Dual Socket, for example). Each stove has multiple burners (Cores); you have multiple cookware like pans, casseroles, pots, etc (Threads). And you (OS) have to manage to cook all that in time, so you move the pan out of the burner to cook something else if needed and put it back to keep it warm.
Hyperthreading
Hyper-threading is intrinsically linked to cores and is best understood as a proprietary technology that allows the operating system to recognize the CPU as having double the number of cores.
In practical terms, a CPU with four physical cores would be recognized by the operating system as having eight virtual cores or capable of dealing with eight threads of execution. The idea is that by doing that, the CPU is expected to better manage the extra load by reordering execution and pipelining the workflow to the actual number of physical cores.
In the context of HPC, as loads are high for the CPU, activating hyper-threading is not necessarily beneficial for intensive numerical operations, and the question of whether that brings a benefit is very dependent on the scientific code and even the particular problem being solved. In our clusters, Hyper-threading is disabled on all compute nodes and enabled on service nodes.
CPU Frequency
Back in the 80s and 90s, CPU frequency was the most important feature of a CPU or at least that was how it was marketed.
Other names for CPU frequency are “clock rate”, or “clock speed”. CPUs work in steps instead of a continuous flow of information. Today, the speed of the CPU is measured in GHz, or how quickly the processor can process instructions in any given second (clock cycles per second). 1 Hz equals one cycle per second, so a 2 GHz frequency can handle 2 billion instructions for every second.
The higher the frequency, the more operations can be done. However, today that is not the whole story. Modern CPUs have complex CPU extensions (SSE, AVX, AVX2, and AVX512) that allow the CPU to execute several numerical operations on a single clock step.
On the other hand, CPUs can now change the speed up to certain limits, raising and lowering the value if needed. Sometimes raising the CPU frequency of a multicore CPU means that some cores are disabled.
One technique used to increase the performance of a CPU core is called overclocking. Overclocking is when the base frequency of a CPU is altered beyond the manufacturer’s official clock rate by user-generated means. In HPC, overclocking is not used, as doing so increases the chances of instability of the system. Stability is a well-regarded priority for a system intended for multiple users conducting scientific research.
Cache
The cache is a high-speed momentary memory device part of the CPU to facilitate future retrieval of data and instructions before processing. It’s very similar to RAM in that it acts as a temporary holding pen for data. However, CPUs access this memory in chunks, and the mapping to RAM is different.
Contrary to RAM, whose modules are independent hardware, cache sits on the CPU itself, so access times are significantly faster. The cache is an important portion of the production cost of a CPU, to the point where one of the differences between Intel’s main consumer lines, the Core i3s, i5s, and i7s, is the size of the cache memory.
There are several cache memories inside a CPU. They are called cache levels, or hierarchies, a bit like a pyramid: L1, L2, and L3. The lower the level the closer to the core.
From the HPC perspective, the cache size is an important feature for intensive numerical operations. Many CPU cycles are lost if you need to bring data all the time from the RAM or, even worse, from the Hard Drive. So, having large amounts of cache improves the efficiency of HPC codes. You, as an HPC user, must understand a bit about how cache works and impacts performance; however, users and developers have no direct control over the different cache levels.
Learn to read computer specifications
One of the central differences between one computer and another is the CPU, the chip or set of chips that control most of the numerical operations. When reading the specifications of a computer, you need to pay attention to the amount of memory, whether the drive is SSD or not, the presence of a dedicated GPU card, and several factors that could or could not be relevant for your computer. Have a look at the CPU specifications on your machine.
Intel
If your machine uses Intel Processors, go to https://ark.intel.com and enter the model of CPU you have. Intel models are, for example: “E5-2680 v3”, “E5-2680 v3”
AMD
If your machine uses AMD processors, go to https://www.amd.com/en/products/specifications/processors and check the details for your machine.
Storage
Storage devices are another area where general supercomputers and HPC clusters differ from normal computers and consumer devices. On a normal computer, you have, in most cases, just one hard drive, maybe a few in some configurations, but that is all. Storage devices are measured by their capacity to store data and the speed at which the data can be written and retrieved from those devices. Today, hard drives are measured in GigaBytes (GB) and TeraBytes (TB). One Byte is a sequence of 8 bits, with a bit being a zero or one. One GB is roughly one billion (10^9) bytes, and a TB is about 1000 GB. Today, it is common to find Hard Drives with 8 or 16 TB per drive.
One HPC cluster’s special storage is needed. There are mainly three reasons for that: you need to store a far larger amount of data. A few TB is not enough; we need 100s of TB, maybe Peta Bytes, ie, 1000s of TB. The data is read and written concurrently by all the nodes on the machine. Speed and resilience is another important factor. For that reason, data is not stored; data is spread across multiple physical hard drives, allowing faster retrieval times and preserving the data in case one or more physical drives fail.
Network
Computers today connect to the internet or other computers via WiFI or Ethernet. Those connections are limited to a few GB/s too slow for HPC clusters where compute nodes need to exchange data for large computational tasks performed by multiple compute nodes simultaneously.
On HPC clusters, we find very specialized networks that are several times faster than Ethernet in several respects. Two important concepts when dealing with data transfer are Band Width and Latency. Bandwidth is the ability to transfer data across a given medium. Latency relates to the obstruction that data faces before the first bit reaches the other end. Both elements are important in HPC data communication and are minimized by expensive network devices. Examples of network technologies in HPC are Infiniband and OmniPath.
WVU High-Performance Computer Clusters
West Virginia University has two main clusters: Thorny Flat and Dolly Sods, our newest cluster that is specialized in GPU computing.

Thorny Flat
Thorny Flat is a general-purpose HPC cluster with 178 compute nodes; most nodes have 40 CPU cores. The total CPU core count is 6516 cores. There are 47 NVIDIA GPU cards ranging from P6000, RTX6000, and A100.
Dolly Sods
Dolly Sods is our newest cluster, and it is specialized in GPU computing. It has 37 nodes and 155 NVIDIA GPU cards ranging from A30, A40 and A100. The total CPU core count is 1248.
Command Line
Using HPC systems often involves the use of a shell through a command line interface (CLI) and either specialized software or programming techniques. The shell is a program with the special role of having the job of running other programs rather than doing calculations or similar tasks itself. What the user types goes into the shell, which then figures out what commands to run and orders the computer to execute them. (Note that the shell is called “the shell” because it encloses the operating system in order to hide some of its complexity and make it simpler to interact with.) The most popular Unix shell is Bash, the Bourne Again SHell (so-called because it’s derived from a shell written by Stephen Bourne). Bash is the default shell on most modern implementations of Unix and in most packages that provide Unix-like tools for Windows.
Interacting with the shell is done via a command line interface (CLI) on most HPC systems. In the earliest days of computers, the only way to interact with early computers was to rewire them. From the 1950s to the 1980s most people used line printers. These devices only allowed input and output of the letters, numbers, and punctuation found on a standard keyboard, so programming languages and software interfaces had to be designed around that constraint and text-based interfaces were the way to do this. Typing-based interfaces are often called a command-line interface, or CLI, to distinguish it from a graphical user interface, or GUI, which most people now use. The heart of a CLI is a read-evaluate-print loop, or REPL: when the user types a command and then presses the Enter (or Return) key, the computer reads it, executes it, and prints its output. The user then types another command, and so on until the user logs off.
Learning to use Bash or any other shell sometimes feels more like programming than like using a mouse. Commands are terse (often only a couple of characters long), their names are frequently cryptic, and their output is lines of text rather than something visual like a graph. However, using a command line interface can be extremely powerful, and learning how to use one will allow you to reap the benefits described above.
Secure Connections
The first step in using a cluster is establishing a connection from our laptop to the cluster. When we are sitting at a computer (or standing, or holding it in our hands or on our wrists), we expect a visual display with icons, widgets, and perhaps some windows or applications: a graphical user interface, or GUI. Since computer clusters are remote resources that we connect to over slow or intermittent interfaces (WiFi and VPNs especially), it is more practical to use a command-line interface, or CLI, to send commands as plain text. If a command returns output, it is printed as plain text as well. The commands we run today will not open a window to show graphical results.
If you have ever opened the Windows Command Prompt or macOS Terminal, you have seen a CLI. If you have already taken The Carpentries’ courses on the UNIX Shell or Version Control, you have used the CLI on your local machine extensively. The only leap to be made here is to open a CLI on a remote machine, while taking some precautions so that other folks on the network can’t see (or change) the commands you’re running or the results the remote machine sends back. We will use the Secure SHell protocol (or SSH) to open an encrypted network connection between two machines, allowing you to send & receive text and data without having to worry about prying eyes.
SSH clients are usually command-line tools, where you provide the remote
machine address as the only required argument. If your username on the remote
system differs from what you use locally, you must provide that as well. If
your SSH client has a graphical front-end, such as PuTTY or MobaXterm, you will
set these arguments before clicking “connect.” From the terminal, you’ll write
something like ssh userName@hostname, where the argument is just like an
email address: the “@” symbol is used to separate the personal ID from the
address of the remote machine.
When logging in to a laptop, tablet, or other personal device, a username, password, or pattern is normally required to prevent unauthorized access. In these situations, the likelihood of somebody else intercepting your password is low, since logging your keystrokes requires a malicious exploit or physical access. For systems like running an SSH server, anybody on the network can log in, or try to. Since usernames are often public or easy to guess, your password is often the weakest link in the security chain. Many clusters, therefore, forbid password-based login, requiring instead that you generate and configure a public-private key pair with a much stronger password. Even if your cluster does not require it, the next section will guide you through the use of SSH keys and an SSH agent to both strengthen your security and make it more convenient to log in to remote systems.
Exercise 1
Follow the instructions for connecting to the cluster. Once you are on Thorny, execute
$> lscpuOn your browser, go to https://ark.intel.com and enter the CPU model on the cluster’s head node.
Execute this command to know the amount of RAM on the machine.
$> lsmem
High-Performance Computing and Geopolitics

Western democracies are losing the global technological competition, including the race for scientific and research breakthroughs and the ability to retain global talent—crucial ingredients that underpin the development and control of the world’s most important technologies, including those that don’t yet exist.
The Australian Strategic Policy Institute (ASPI) released in 2023 a report studying the position of big powers in 44 critical areas of technology.
The report says that China’s global lead extends to 37 out of the 44 technologies. Those 44 technologies range from fields spanning defense, space, robotics, energy, the environment, biotechnology, artificial intelligence (AI), advanced materials, and key quantum technology areas.
![]()
From that report, the US still leads in High-Performance Computing. HPC is a critical enabler for innovation in other essential technologies and scientific discoveries. New materials, drugs, energy sources, and aerospace technologies. They all rely on simulations and modeling carried out with HPC clusters.
Key Points
Learn about CPUs, cores, and cache, and compare your machine with an HPC cluster.
Identify how an HPC cluster could benefit your research.