Introduction to HPC
Overview
Teaching: 30 min
Exercises: 30 minQuestions
What is High-Performance Computing
Objectives
Learn the basic terminology in HPC
High Performance Computing
High-Performance Computing is about size and speed. A HPC cluster is made of tens, hundreds or even thousands of relatively normal computers specially connected to perform intensive computational operations. In most cases those operations involve large numerical calculations that take too much time to perform or simply unfeasible to perform on a normal machine.
This is a very pragmatic tutorial. We will focus more on examples, exercises, hands on than on theoretical stuff. The idea is that after these two days of workshop you learn how to enter into the cluster, compile code, execute using the queue system and transfer data in an out the cluster.
Due to the pragmatic approach of this year. The notes focus on the strict know-how and the exercises.
Exercise 1
Check your computer, gather information about the CPU, number of Cores, Total RAM memory and Hard Drive.
The purpose of this exercise is to compare your machine with our clusters
You can see specs for our clusters at https://docs.hpc.wvu.edu/text/82.Spruce.html and https://docs.hpc.wvu.edu/text/83.ThornyFlat.html
Try to gather an idea on the Hardware present on your machine and see the hardware we have on Spruce Knob or Thorny Flat
Here are some tricks to get that data from several Operating Systems
Windows 10
Open the File Explorer, search for the icon, “This PC” and click with the right mouse button and click properties.
You should be able to see something like:
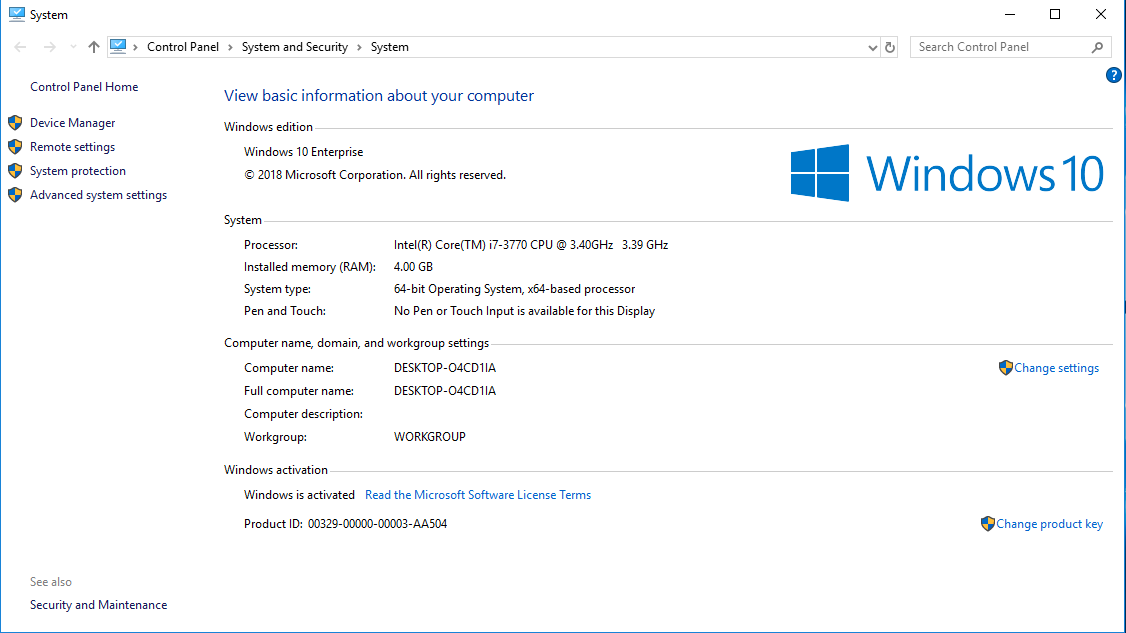
Mac
On MacOS click on the top left corner (The Apple Icon), click on “About this Mac” and you will get the basic information.
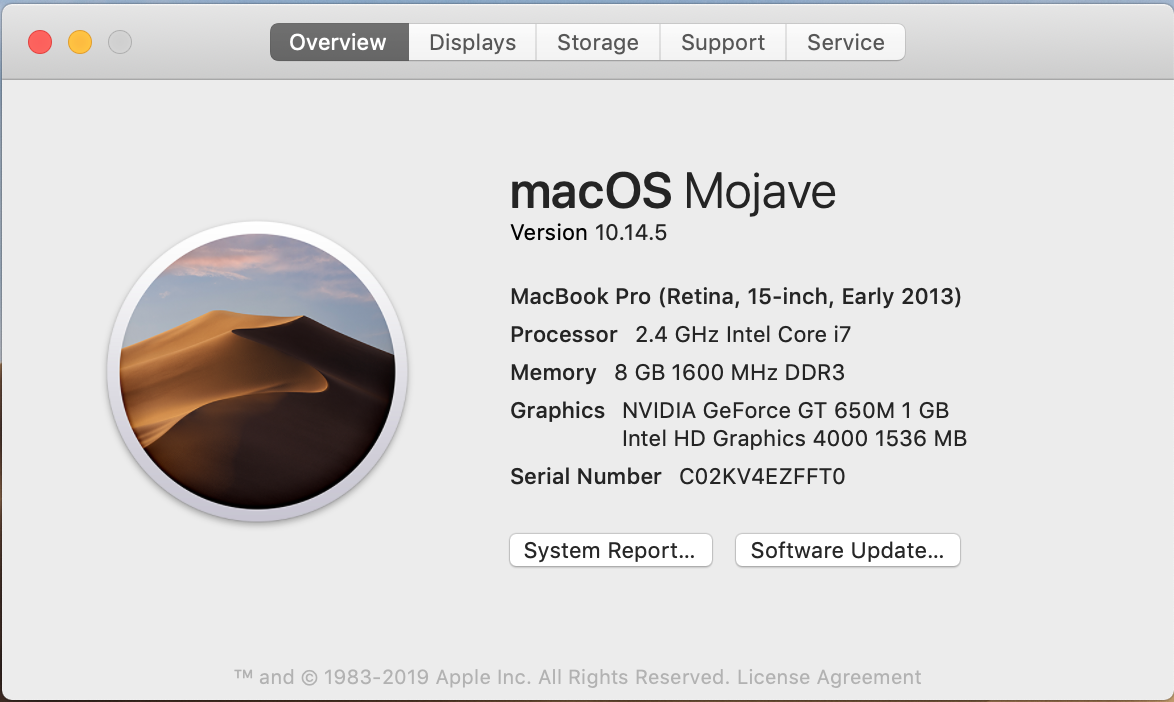
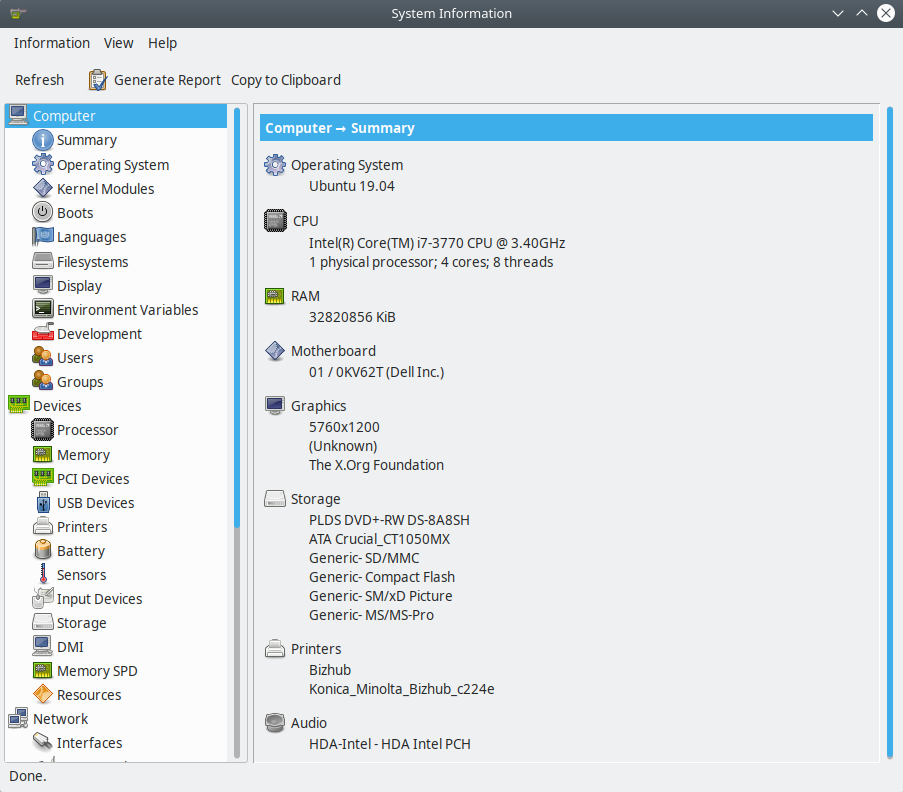
If you want more data click on “System Report…” and you will get:
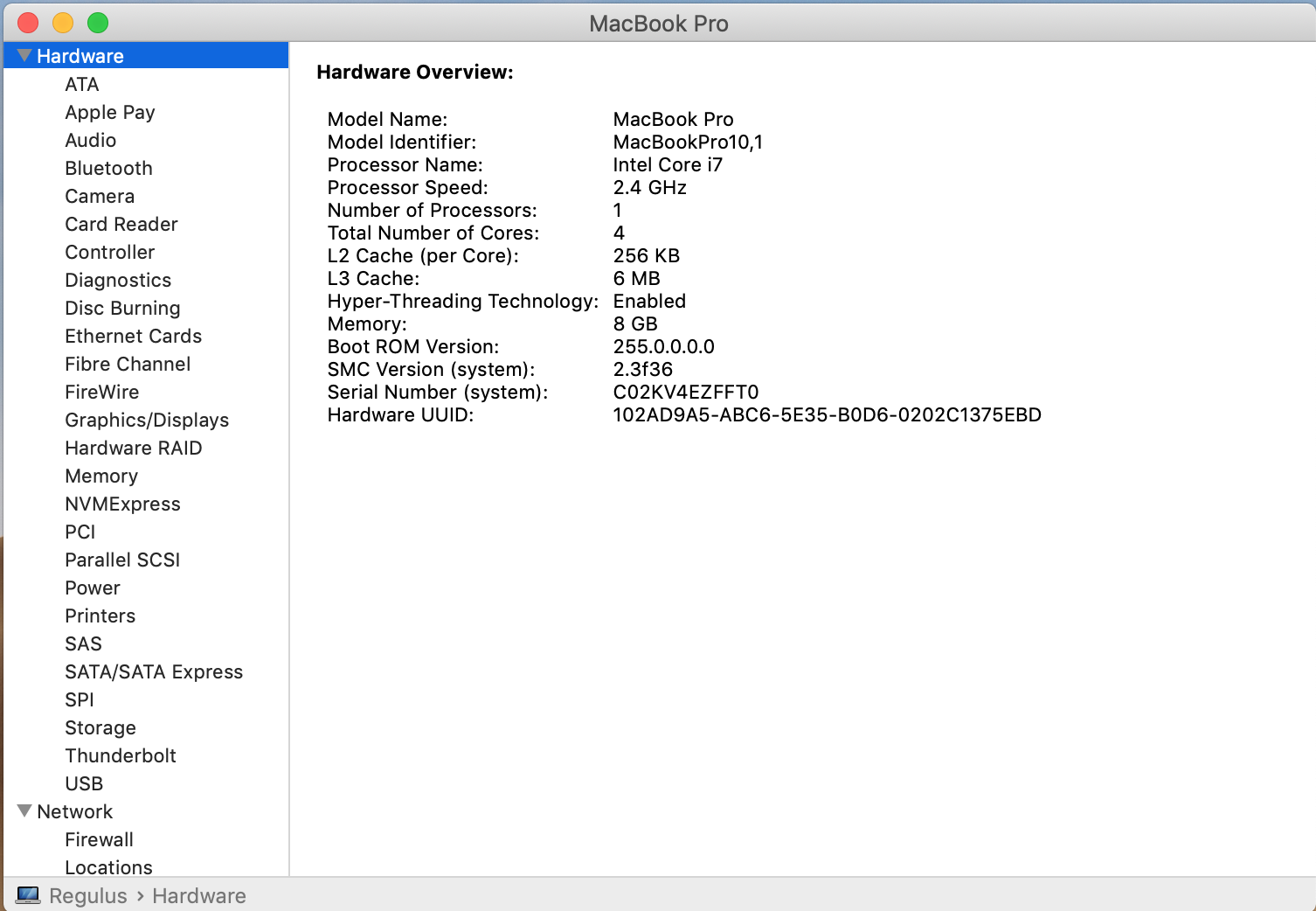
Linux
In Linux gathering the data from a GUI depends a lot from more from the exact distribution you are using here some tools that you can try
KDE Info Center
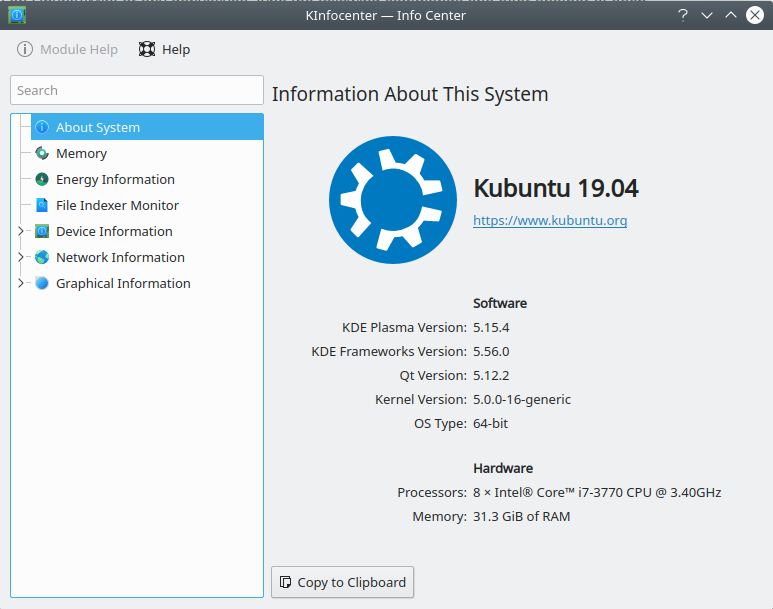
Linux Mint Cinnamon System Info
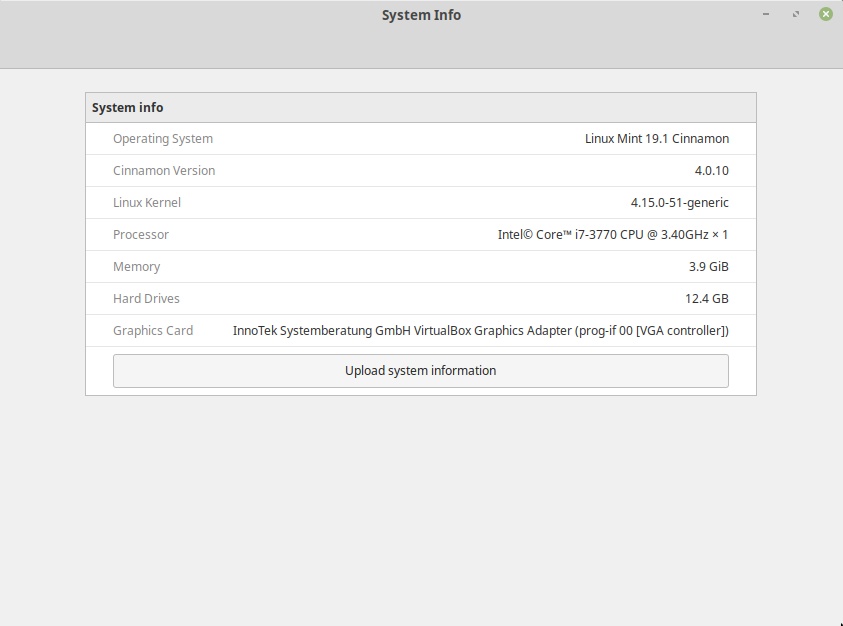
Linux Mint Cinnamon System Info
It is probably easier from the command line CLI but this is too early of a stage for that. In case you know how to get access to a terminal here are a few commands to try:
bash-4.2# cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 63
model name : Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz
stepping : 2
microcode : 0x1
cpu MHz : 2494.224
cache size : 16384 KB
physical id : 0
siblings : 1
core id : 0
cpu cores : 1
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology eagerfpu pni pclmulqdq vmx ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt arat md_clear spec_ctrl intel_stibp
bogomips : 4988.44
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
bash-4.2# free
total used free shared buff/cache available
Mem: 1882216 174700 1309236 17008 398280 1526060
Swap: 0 0 0
Central Processing Units
CPU Brands and Product lines
There are only two manufacturers that matter for PC consumer computing: Intel and AMD. There are several others manufacturers of CPUs but those are mostly for vertical markets like CPUs for SmartPhones, Photo Cameras, Musical Instruments, or very specialized HPC clusters. It is very unlikely that your computer have a CPU different from Intel or AMD.
More than a decade ago, the main featured used for marketing purpuses on a CPU was the speed. That have changed now, as CPUs are not getting faster, but include complexity that is hard to market with a single number. That is why CPUs are now marketed with “Product Lines” and the Models are less representative of the actual characteristics of a given machine.
For example, Intel Core i3 processors are marketed to entry level machines more tailored to basic computing tasks like word processing and web browsing. On the other hand, Intel’s Core i7 and i9 processor range are for high-end products aimed at the top of the line gaming rigs able to run the most recent titles at ridiculously high FPS and resolutions. Machines for enterprise usage are usually under the Xeon Line.
On AMD’s side, you have the Athlon line aimed at entry-level users, all the way to the Ryzen 7 designed mostly for enthusiasts and gamers. AMD also has prduct lines for enterprises like EPYC Server Processors.
Cores
The next term to understand is core.
Consumer level CPUs up to 2000s only had one core, but Intel and AMD both hit a brick wall with incremental clock speeds improvements. The heat and power comsumption scales non linearly with the CPU speed. That brings us to the current trend and instead of a single core, CPUs now have two, three, four, eight or sixteen cores on a single CPU.
Each core is actually a full featured CPU, but due to marketing purposes, the term core is now applied and the term CPU is the name for the full piece of Integrated Circuits that contains several cores.
Hyperthreading
Hyperthreading is intrinsically linked to cores and is best understood as a proprietary technology that allows the operating system, to recognize the CPU as having double the amount of cores.
In practical terms, a CPU with four physical cores would be recognized by the operating system as having eight virtual cores, or eight threads. The idea is that by doing that it is expected that the CPU is able to better manage the extra load, by faking the OS about the actual number of physical cores.
In the context of HPC there is still debate if activating Hyperthreading is beneficial for intensive numerical operations and the answer is very dependent on the code. In our clusters Hyperthreading is disabled on all compute nodes and enable on service nodes.
CPU Frequency
Back in the 80s and 90s CPU frequency was the most important feature of a CPU or at least that was the way it was marketed.
Other names for CPU frequency are “clock rate”, or “clock speed”. CPUs work by steps instead of continuous flow of information. The speed of the CPU is today measured in GHz, or how quickly the processor can process instructions in any given second (clock cycles per second). 1 Hz equals one cycle per second, so a 2 GHz frequency can handle 2 billion instructions for every second.
The higher the frequency the more operations can be done. However, today that is not the whole story. Modern CPUs have complex CPU extensions that allow the CPU to execute several numerical operations on a single clock step. You will here about those as SSE, AVX, AVX2 and AVX512.
From another side, CPUs are now able to change the speed up to certain limits, raising and lowering the value if needed. Sometimes raising the CPU frequency of a multicore CPU means that some cores are disabled as result.
Another technique used often by gamers is overclocking. Overclocking, is when the frequency is altered beyond the manufaturer’s official clock rate by user-generated means. In HPC this is often not applied as overclocking increases the chances of instability of the system. Something that for numerical purpuses could be catastrophic.
Cache
Cache is a high-speed momentary memory format assigned to the CPU to facilitate future retrieval of data and instructions before processing. It’s very similar to RAM in the sense that it acts as a temporary holding pen for data. However CPU’s access this memory in chunks and the mapping to RAM is different.
Contrary to RAM that are independent pieces of hardware, cache sits on the CPU itself, so the access times are significantly faster. The Cache is an important portion of the production cost of a CPU, to the point where one of the differences between Core i3 i5 and i7 is basically the size of the Cache memory.
There are actually several cache memories inside a CPU. They are called cache levels, or hierarchies, a bit like a pyramid: L1, L2, and L3. The lower the level the closer to the core.
L1 is the fastest cache and the first port of call for a CPU hunting down data. In modern processors, two split compartments make up the L1 cache, one for data and one for instructions, and every core is assigned an exclusive portion of the L1 cache.
L2 is bigger than L1, and consequently slower due to the processor having to trawl through more data. L3, on the other hand, is shared among all the cores and offers more space, but is slower.
From the HPC perspective for intensive numerical operations. The cache size is an important feature. Many CPU cycles are lost if you need to bring data all the time from the RAM or even worst from the Hard Drive. So having large amounts of cache improves the efficiency of HPC codes.
Exercise 2
One of the central differences between one computer and another are the CPU, the chip or set of chips that control most of the numerical operations, GPUs are also another way of cruch numbers on a computer but we will keep them for the next exercise.
Intel
If your machine uses Intel Processors go to https://ark.intel.com and enter the model of CPU you have, Intel models are for example: “E5-2680 v3”, “E5-2680 v3”
AMD
If your machine uses AMD processors go to https://www.amd.com/en/products/specifications/processors and check the details for your machine.
Connecting to the cluster
Now it is time to get into the cluster.
On MacOS and Unix/Linux, open a terminal shell and type:
$> ssh <username>@<hostname>
or
$> ssh -X <username>@<hostname>
Where <username> is your WVU Login account username and <hostname> is the name of the cluster you wish to connect to.
The -X option is used to forward X windows applications running on the server to be forwarded to your local machine.
Remember that the $> symbols above are there to indicate a command on the terminal, you should not enter those initial characters.
We currently have two clusters Thorny Flat and Spruce Knob
Spruce Knob
To connect to Spruce Knob use the following command::
$ ssh <username>@spruce.hpc.wvu.edu
Note: Two-factor authentication is required to connect to Spruce Knob when not on WVU’s Main Campus Network. More about WVU’s Two-Factor Authentication system can be found here
Thorny Flat
To connect to Thorny Flat, you will first have to connect to WVU’s SSH gateway server. This gateway server will allow you to connect the Thorny Flat, which is hosted at the Pittsburgh Supercomputing Center.::
$ ssh <username>@ssh.wvu.edu
More information on WVU’s Gateway Service can be found here. When your account is created to for Thorny Flat, you will automatically be approved for access to WVU’s SSH Gateway Service.
Note: Two-factor authentication is required to connect to WVU’s Gateway Service. More about WVU’s Two-Factor Authentication system can be found here
then:
$ ssh tf.hpc.wvu.edu
Logging In
When your SSH access is granted, you will be prompted with a login message with helpful commands and updates about the cluster.
At this point, you will get a terminal prompt such as::
<username>@srih0001:~$
All the commands executed from now on are happening on a remote machine, the Spruce Knob head node, this is the place were most of your direct interaction with the cluster happens.
Logging Out
Logging out of a cluster can be done with the exit command::
$> exit
The exit command will attempt to terminate any process running on the head. In some cases, you will get an error that jobs are either currently running or currently stopped. You can view stopped jobs using the jobs command::
$> jobs -l
[1]+ 3325 Stopped vim script56.py
The output of jobs -l will give you the job PID number (in this case 3325) and the command (vim script56.py). To kill jobs preventing successful log out, use the kill command::
$> kill -s 9 3325
Once all jobs are terminated, the exit command will close the connection to the host.
Exercise 3
Get into Spruce with your training account and execute the commands ls, date and cal
Exit from Spruce with exit
Key Points
Learn about CPUs, cores, cache and comparing your own machine with a HPC cluster